
My first semester at Purdue, I took CS540: Database Systems. While I had worked on production-scale databases, I had never formally studied them. To me, the core idea of a good database design is about understanding how data actually gets used. Whether you're optimizing for reads or writes, whether you're running transactional workloads or analytical queries, it all comes down to matching your storage to your access patterns. During that class, we looked at all kinds of data: relational, non-relational, time series, key-value stores. One type of data, however, that I could not fully categorize was application logs.
Logs are strange. They are append-heavy like event streams, semi-structured like documents, queried like analytical systems, andsearched like text databases. They don't fit neatly into any single category. And honestly, for the longest time, I just accepted that logs were this necessary evil that we had to store and occasionally search through.
Then I came across a report published by Elastic, that covered how much organizations spend on log storage. The numbers were crazy! Roughly 15% of Infra cost just accounted for log storage. ~42% of the companies that took part in that survey were actively looking for optimizing this cost. That got me digging more into log storage and observability. I started asking people how and where they stored application logs, and what their debugging workflow looked like. After some research and thought, I realized that most of the stuff in logs was garbage and did not deserve a place on the disk. The same fifteen log patterns, firing millions of times a day. The timestamp changes. The user ID changes. Sometimes a request duration. But the rest remains identical.
2024-01-15T10:23:45Z DEBUG 1234 DB SELECT table=sessions 5 rows 12ms
2024-01-15T10:23:46Z DEBUG 5678 DB SELECT table=sessions 2 rows 8ms
2024-01-15T10:23:47Z DEBUG 9999 DB SELECT table=sessions 14 rows 31msThree seemingly unique strings, but there's really just one template and three sets of parameters:
Template: "{ts} DEBUG {num} DB SELECT table=sessions {rows} {duration}"
Parameters:
["2024-01-15T10:23:45Z", "1234", "5 rows", "12ms"]
["2024-01-15T10:23:46Z", "5678", "2 rows", "8ms"]
["2024-01-15T10:23:47Z", "9999", "14 rows", "31ms"]Instead of storing those three identical strings over and over, you store one template and three tiny parameter sets. Then you let DuckDB's columnar compression handle the rest. We're seeing 76–81% compression on real workloads, and here's the beautiful part: every single line is perfectly reconstructable.
But extracting templates from unstructured logs? That's where the work actually happens. I started with regex. I asked Claude to write a regex that would grab timestamps, log levels, messages. But it fell apart immediately. Logs are fundamentally chaotic. Every application logs differently. There's no one regex that works for everything. I needed something smarter.
---
Drain Algorithm
That's when I found the Drain algorithm. Drain is a streaming log parser that groups log lines into clusters without requiring any regex configuration. The workflow is divided into two major steps.
Step 1: Tokenize
Every incoming line gets split into tokens. LogTokenizer handles this with whitespace splitting, but the tokenizer is also aware of multi-word structures like quoted strings and certain compound values.
Once you have tokens, TokenClassifier labels each one:
| Token | Type |
|---|---|
2024-01-15T10:23:45Z | TIMESTAMP |
12ms | NUM (numeric-ish) |
550e8400-e29b-41d4-a716-446655440000 | UUID |
d41d8cd98f00b204e9800998ecf8427e | HASH |
192.168.1.1 | IP |
SELECT | WORD (static) |
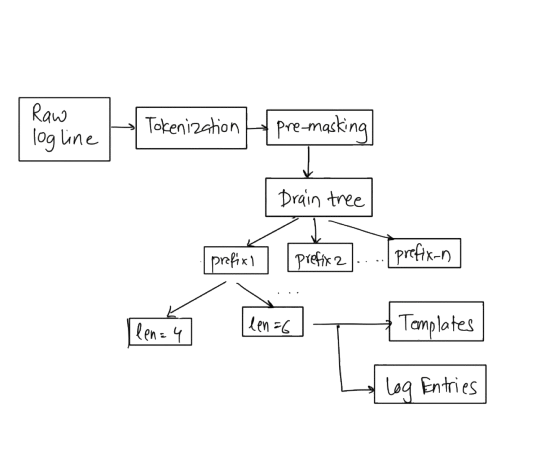
The WORD tokens are potentially static. TokenClassifier has a regex for obvious variables, such as timestamps, UUIDs, IPs, hashes, etc. These get replaced with placeholders like {ts} or {uuid} upfront. It is called pre-masking. Application-specific tokens like req-755556 don't get this treatment. They have to go through the drain-tree before they are marked as wildcards.
Step 2: Drain Tree
Every incoming log line finds its place in the Drain Tree using two keys: how many tokens it has, and what its first non-wildcard word is.
Root
├── length=6
│ ├── "User" → [cluster: "User {num} logged in from {ip}"]
│ └── "DB" → [cluster: "DB {num} SELECT table={word}"]
└── length=8
└── "Cache" → [cluster: "Cache {num} hit for key {uuid}"]When a new line arrives, it walks this tree to find the closest existing cluster. Closeness is measured by how many static tokens match. A line that agrees on 4 out of 6 tokens scores higher than one that agrees on 2.
If the best match scores above the similarity threshold (default 50%), the line merges into that cluster. Any position where the line disagrees with the cluster becomes a wildcard. If nothing scores high enough, a new cluster starts.
At this point, a cluster is a candidate and not a template yet. Only after lockAfterN is reached (default: 10) does it get committed to the database as a permanent template. Before that, lines go into raw_logs. Drain doesn't need to see every log line to learn a template. After seeing two lines that differ only in a few positions, it has enough signal to generalize. Once a cluster is seen
lockAfterN times, it locks the pattern and commits that as a template to the database.
---
Storage Model
Logslim persists data across three logical layers:
- raw ingestion,
- structural templates,
- compact reconstructed entries
During Drain’s initial learning phase, unmatched logs are temporarily stored verbatim in raw_logs so no information is lost while templates stabilize. Once patterns are learned, each distinct structure is stored exactly once in templates, along with occurrence metadata, while individual log events in log_entries reference the template ID and persist only the variable parameters plus timestamp metadata. Timestamps are stored as epoch millisecond BIGINTs instead of ISO strings to improve columnar compression efficiency in DuckDB and reduce per-row overhead at scale. Parameters are stored as ordered JSON arrays instead of key-value maps because the template already defines what each position represents. This keeps serialization simpler and reduces storage overhead. Multi-line payloads such as JVM stack traces are attached separately as raw continuation blobs. This allows Logslim to reconstruct original logs.
---
Compaction
After logs have been ingested and patterns have stabilized, you can run a compaction phase. It takes the templates, entries, and raw logs, moves them into compressed Parquet files, and replaces the original tables with views. Those views are UNION ALL queries that combine the archived Parquet data with new incoming logs.
Compression gets even better over time because repeated template patterns give the columnar encoder more to work with. It's like having a more repetitive message to compress—better ratios all around.
The tricky part was getting queries to work after compaction. Once you've turned tables into views, all your queries have to go through those views. But it actually works well—DuckDB pushes predicates into the Parquet scan, so time-range queries on the timestamp column are fast because Parquet stores min/max statistics for each chunk.
The code just checks once whether the base table names are views or real tables. If they're views, you know compaction happened, so all new inserts go to the _live tables. Clean and invisible to the rest of the system.
---
Continuous Ingestion from Kafka
For real-time log ingestion, logslim consume subscribes to a Kafka topic and runs indefinitely:
logslim consume \
--topic app-logs \
--bootstrap-servers kafka-broker:9092 \
--group-id logslim-prod \
--batch-size 5000 \
--flush-interval PT5S \
--compact-interval PT10MA few implementation choices here that matter:
Single-threaded. Poll, write, and compact share one thread. DuckDB has a one-writer-per-process constraint. Attempting to write from multiple threads causes contention. Running single-threaded avoids this entirely and keeps the code simple, however, it comes with a throughput cost.
At-least-once delivery. Kafka offsets are committed only after a batch is successfully written. If the JVM crashes mid-batch, the next run re-reads from the last committed offset and re-processes those lines.
Periodic compaction. The --compact-interval flag triggers an in-process compaction cycle. This keeps the live DuckDB file small, which matters because DuckDB WAL growth is proportional to uncompacted write volume.
Graceful shutdown. SIGINT triggers a shutdown hook: flush the in-flight batch, commit offsets, run one final compact, then exit. This prevents the system from havint to deal with data loss or half-written state.
---
Reconstruction: Getting Back to Byte-Exact
Here's maybe the coolest part: you can always get back the exact original log, byte-for-byte.
The reconstruction algorithm is straightforward. You scan the template pattern for placeholders like {slot_name}, then substitute each one with the corresponding value from the parameter array. If there's a multi-line payload stored separately, you append that too.
The only wrinkle is when you have duplicate types—like three different numbers in one template. You can't just call them all {num}. So the system assigns indexed names like num, num_1, num_2 and matches them in order during reconstruction.
It works. Every single log line comes back exactly as it went in.
Compression is by no means the only intention of Logslim. You don't need Logslim just to store logs in compressed Parquet. There are other methods, such as filesystem compression, to optimize log storage. Logslim instead focuses on extracting structure from repetitive, unstructured logs by converting them into reusable templates and parameterized events. This makes legacy logs easier to query, cluster, analyze, and reason about without requiring teams to first migrate to structured logging frameworks like OpenTelemetry.
Once logs become template-aware, debugging improves because repeated noise collapses into identifiable patterns. Anomaly detection becomes easier because rare or previously unseen templates stand out immediately. Overall log hygiene improves because engineers can reason about systems at the level of events rather than raw text streams.
The code is on GitHub at github.com/mihirrd/logslim. I'm always open to pull requests—just open an issue first if it's something big. Building this has been one of those projects where I learned more than I expected, and I'm curious to see where other people take it.